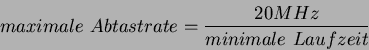Im ersten Schritt laufen jeweils vier gleiche Programme auf dem Simulator ab. Alle Threads haben somit die gleichen Parameter wie Deadline und Periode und laufen unter Guaranteed Percentage mit 25% der verfügbaren Rechenleistung. Die kürzeste Deadline, die noch eingehalten werden kann, wird dann in eine mögliche Abtastrate auf einem Mikrocontroller umgerechnet, der mit 20 MHz getaktet ist, und die Programme auf vier Datenkanälen ausführt.
Die Ergebnisse der verschiedenen Scheduler werden in Abbildung 3.11 mit einem Prozessor verglichen, der nicht mehrfädig ist, aber auch keine zusätzlichen Takte für einen Threadwechsel benötigt. Dieser hypothetische Prozessor würde das Vierfache der Ausführungszeit eines einzelnen Thread brauchen, da er keine Latenzen nutzen kann.
Da alle Deadlines gleich sind, entartet Earliest Deadline First in diesem Fall zu einem Verfahren mit festen Prioritäten und liefert daher auch dieselben Ergebnisse. Für den Meßwertaufnehmer liefern alle Verfahren das gleiche Ergebnis, da die extrem kurze Laufzeit hier kaum Variationen zuläßt.
Tabelle 3.6 zeigt die absoluten Abtastraten, die mit den verschiedenen Verfahren für die Benchmarks erreichbar sind. Dabei ist zu beachten, daß immer vier Dateneingänge gleichzeitig bearbeitet werden.
| ||||||||||||||||||||||||||||||
Es ist zu beobachten, daß bei EDF und Fixed Priority bei Unterschreiten ihrer kleinstmöglichen Deadline der Thread mit der niedrigsten Priorität seine Deadline nicht mehr einhalten kann, da nur dieser zuletzt noch läuft. Bei EDF ist das der Thread mit der höchsten ID, wenn alle Deadlines gleich sind. Bei Least Laxity First und Guaranteed Percentage gehen dagegen alle Deadlines gleichzeitig verloren, weil am Ende alle Threads noch laufen.
In Abbildung 3.12 ist die Anzahl der Threadwechsel aufgetragen, die bei den Verschiedenen Verfahren anfallen. Dabei sind die Threadwechsel nicht berücksichtigt, die aufgrund von Latenzverdeckungen auftreten. Ein nicht mehrfädiger Prozessor würde diese nicht ausführen.
Aus der Grafik ist sofort ersichtlich, daß Least Laxity First und Guaranteed Percentage in der hier beschriebenen Form mit einer Schedulingentscheidung in jedem Takt nicht eingesetzt werden können, wenn der Kontextwechsel in Software erfolgen muß und somit zusätzliche Takte kostet. Man müßte dann Zeitscheiben einsetzen, was die Reaktionszeiten des Echtzeitsystems verschlechtern würde. Außerdem würde auch dann noch ein hoher Overhead entstehen.
Ein Thread mit nur wenigen Befehlen, wie zum Beispiel der beschriebene Meßwertaufnehmer, würde ein Vielfaches seiner eigenen Laufzeit als Overhead verursachen. Für den PicoJava werden etwa 100 Takte für einen Kontextwechsel angegeben. Damit würde ein Durchlauf der vier Meßwertaufnehmer (15+100)*4=460 Takte in Anspruch nehmen. Man könnte also nur noch eine Datenrate von weniger als 43,5 kHz erreichen. Bei den längeren Threads wirkt sich dieser Overhead nur dann so stark aus, wenn feingranulare Scheduling-Verfahren verwendet werden.
Es zeigt sich auch, daß es auf einem mehrfädigen Prozessor sehr wichtig ist, daß das Schedulingverfahren die Threads gut durchmischt. Der Grund dafür liegt darin, daß dann meistens ein ausführbarer Thread vorhanden ist, der die Latenzen der anderen verdecken kann. Bei den gröberen Verfahren wie EDF oder Fixed Priority laufen zuerst die hochpriorisierten Threads, deren Latenzen von niedriger priorisierten genutzt werden können. Wenn gegen Ende einer Periode aber nur noch der Thread mit der niedrigsten Priorität übrigbleibt, können dessen Latenzen nicht mehr verwendet werden, die Prozessorleistung geht verloren.